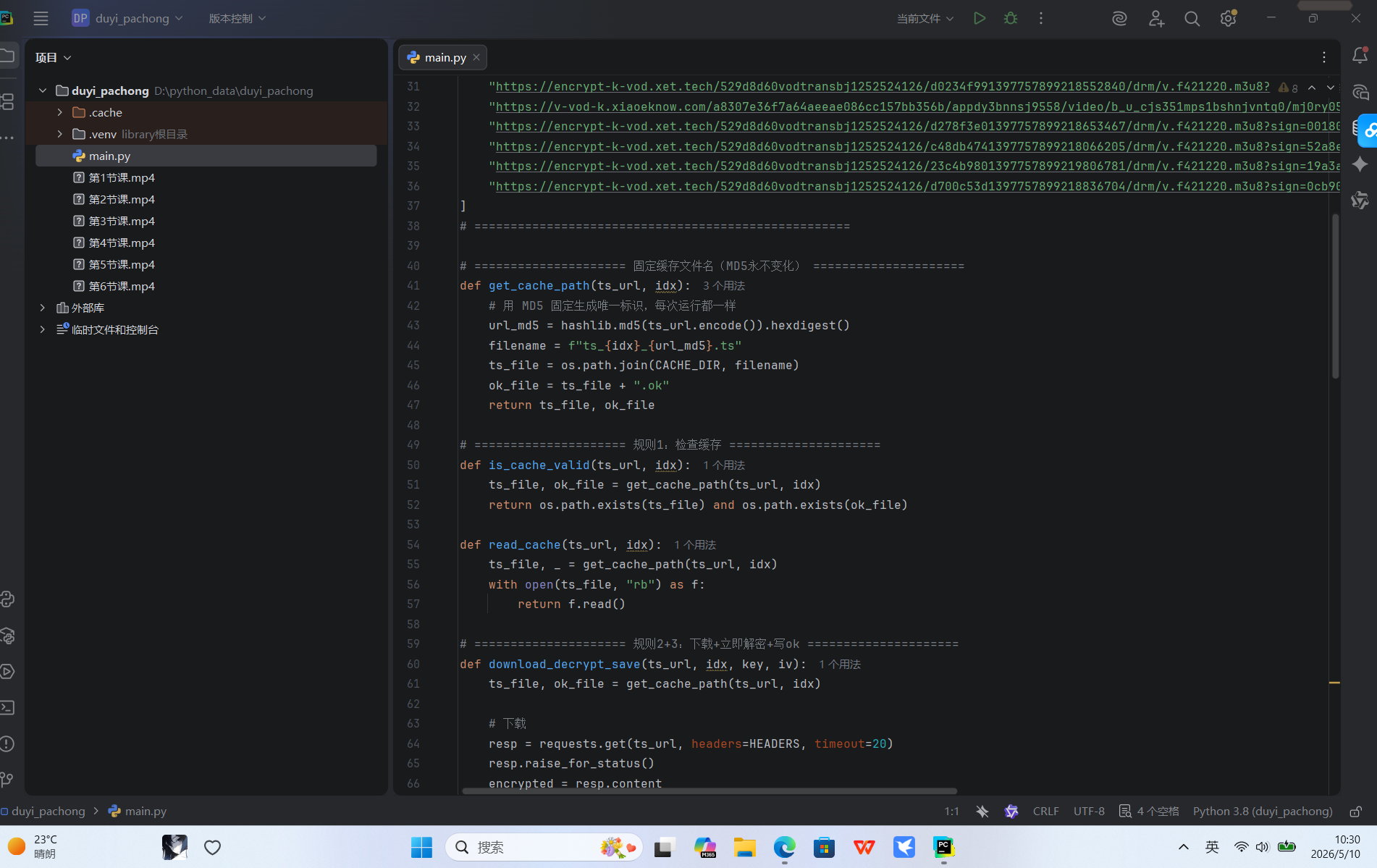
由于我买了一套前端大师课,但是只有10天,所以我想着给他爬下来
先找一下视频链接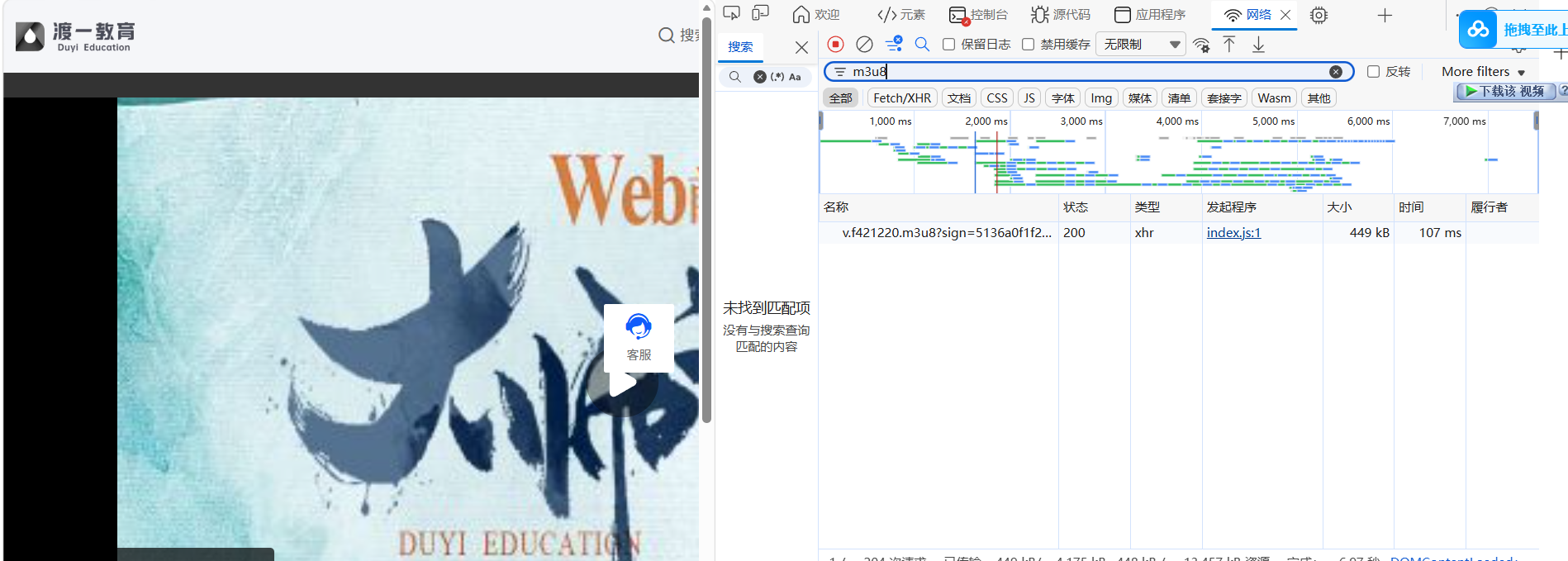
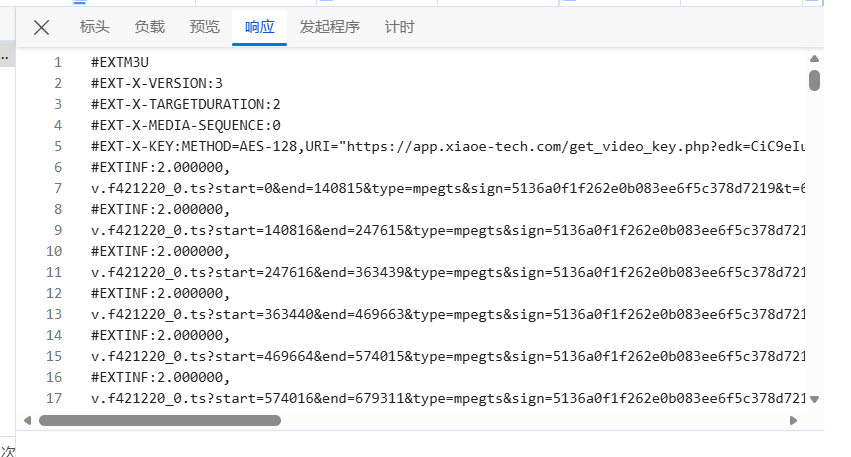
m3u8+AES-128
复制curl后我发现居然没有token和cookie限制,这节课有6个视频
那么,正常思路是从课程首页获取到m3u8的list,然后爬,但是?!我这里只有6个视频,还不如我一个个复制m3u8
有时候写爬虫就是这样,临时爬虫部分数据复制写死反而更快
我们手动把每一节课的 m3u8 链接整理好,放进链接列表里,程序只需要遍历这个列表就行。
每解析一个 m3u8 地址,程序会自动做两件事:
第一,自动从 m3u8 文本里提取出 AES 密钥的请求地址,自动拉取拿到真实密钥;
第二,顺带自动识别拿到播放用的 IV 偏移量,不用我们手动配置改动。
拿到密钥和 IV 之后,就开始逐个处理 TS 分片:
程序先走缓存校验逻辑,根据 TS 链接生成固定不变的唯一标识,映射到 .cache 缓存文件夹里。
先检查本地有没有对应的 .ts 分片文件和配套的 .ok 标记文件,两个文件都齐全,就直接读取本地解密好的分片,不发任何网络请求,省流量还秒加载。
如果缓存文件缺失、或者没有 ok 标记,才会发起网络请求下载当前 TS 分片。
而且是下载完一个分片就立马当场解密,不是等所有分片全部下完再统一解密,效率更高。
单个分片解密完成后,再写入本地缓存保存下来,同时生成 .ok 标记文件,作为正常完成的凭证,下次再运行就可以直接复用本地文件了。
等一节课所有 TS 分片全部下载、解密、缓存校验都完全成功之后,才会按顺序把所有分片合并,输出完整的 MP4 视频;只要有任意一个分片失败,就不合成视频,避免产出损坏、残缺的文件。
而且中途手动停程序、断网、崩溃都没关系,缓存标识是固定的,下次重新运行,会自动跳过已经处理好的分片,只补下缺失的部分,天然支持断点续传。
思路整理好了,直接让豆包生成代码即可